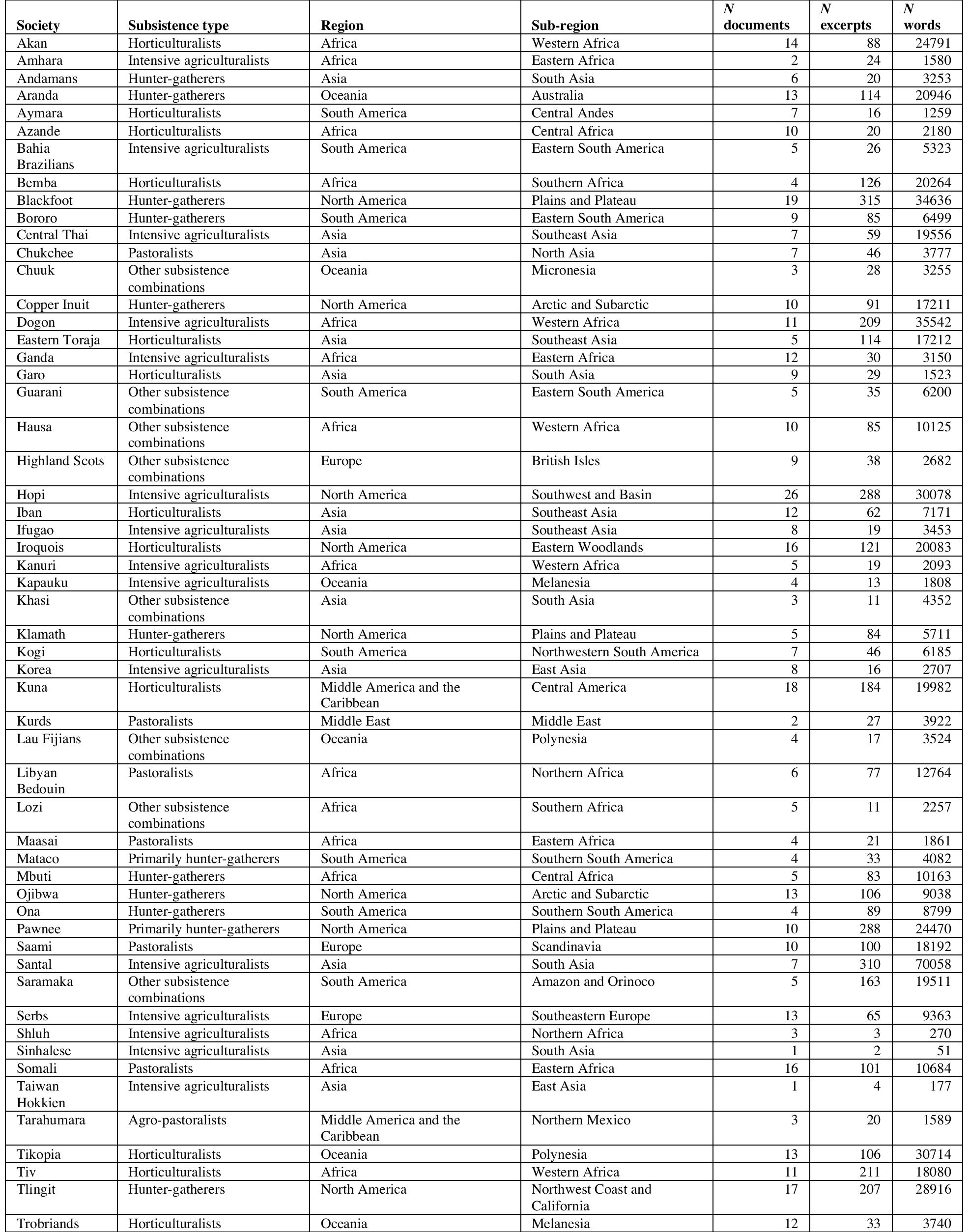
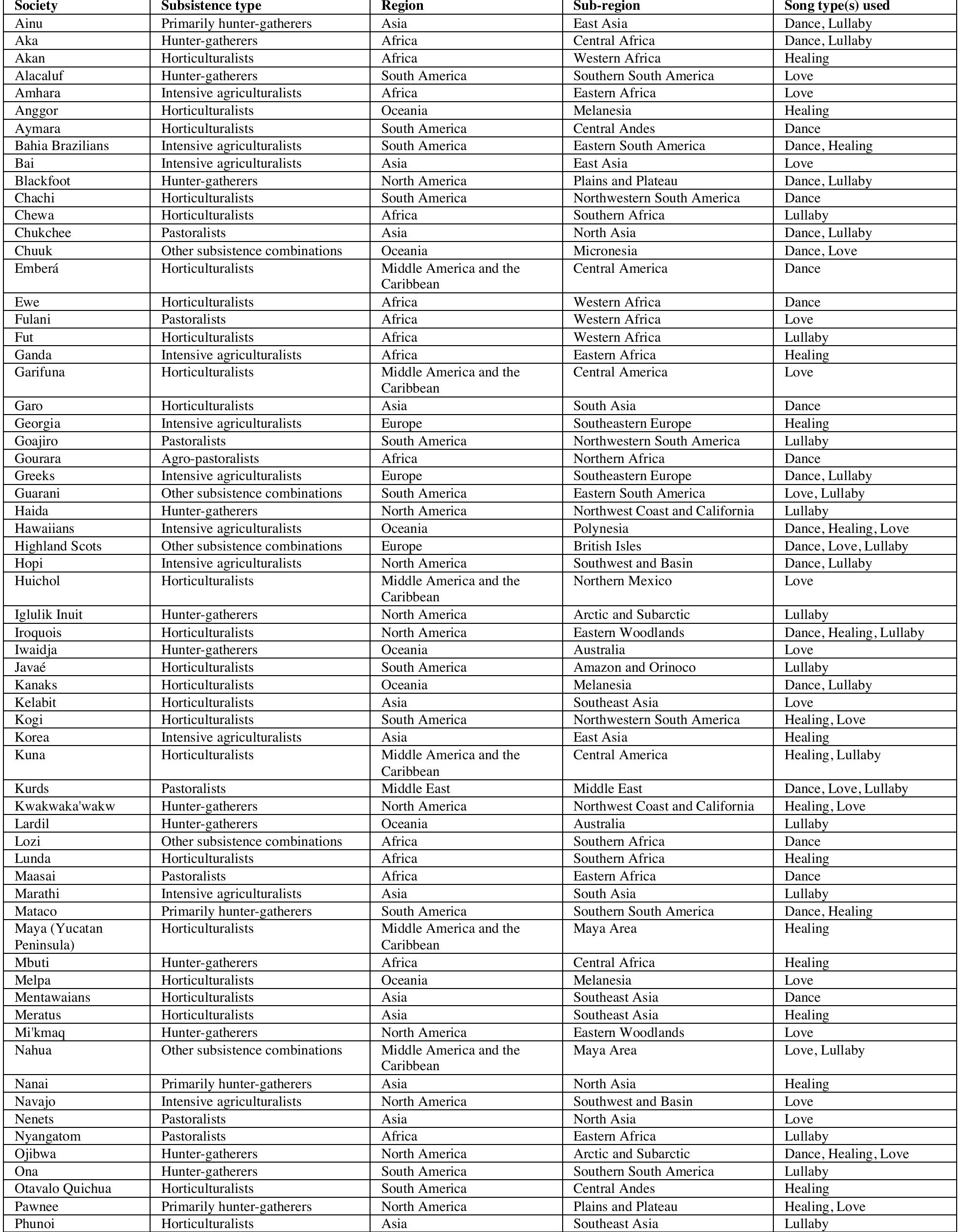
Fig. 2. Patterns of variation in the NHS Ethnography. The figure depicts a projection of a subset of the NHS Ethnography onto three principal components (A). Each point represents the of an excerpt, with points colored by which of four types (identified by a broad search presented here (highlighted circles and B, C, D, E). Density plots (F, G, H) show song types on each dimension. Criteria for classifying song types from the raw tex presented in Table $17. he d posterior mean location for matching keywords and annotations) it falls into: dance (blue), lullaby (green), healing (red), or love (yellow). The geometric centroids of each song type are represented by the diamonds. Excerpts that d single search are not plotted, but can be viewed in the interactive version of this figure http://themusiclab.org/nhsplots, along with all text and metadata. Selected examples of 0 not match any at each song type are ifferences between and annotations are Fig. 3. Society-wise variation in musical behavior. Density plots for each society showing the distributions of musical performances on each of the three principal components (Formality, Arousal, Religiosity). Distributions are based on posterior samples aggregated from corresponding ethnographic observations. Societies are ordered by the number of available documents in the NHS Ethnography (the number of documents per society is displayed in parentheses). Distributions are color-coded based on their mean distance from the global mean (in z-scores; redder distributions are farther from 0). While some societies' means differ significantly from the global mean, the mean of each society's distribution is within 1.96 standard deviations of the global mean of 0. One society (Tzeltal) is not plotted, because it has insufficient observations for a density plot. Asterisks denote society-level mean differences from the global mean. *p < .05; **p < .01; ***p <.001 Table 1. Cross-cultural associations between song and other behaviors. We tested 20 hypothesized associations between song and other behaviors by comparing the frequency of a behavior in song-related passages to that in comparably-sized samples of text from the same sources that are not about song. Behavior was identified with two methods: topic annotations from the Outline of Cultural Materials ("OCM identifiers"), and automatic detection of related keywords ("WordNet seed words"; see Table S19). Significance tests compared the frequencies in the passages in the full Probability Sample File containing song-related keywords ("Song freq.") with the frequencies in a simulated null distribution of passages randomly selected from the same documents ("Null freq."). ***p < 001, **p < .01, *p < .05, using adjusted p-values (S8); 95% intervals for the null distribution are in brackets. After controlling for ethnographer bias via the simulation method described above, and adjusting Fig. 6. Signatures of tonality in the NHS Discography. Histograms (A) representing the ratings of tonal centers in all 118 songs, by thirty expert listeners, show two main findings. First, most songs' distributions are unimodal, such that most listeners agreed on a single tonal center (represented by the value 0). Second, when listeners disagree, they are multimodal, with the most popular second mode (in absolute distance) 5 semitones away from the overall mode, a perfect fourth. The music notation is provided as a hypothetical example only, with C as a reference tonal center; note that the ratings of tonal centers could be at any pitch level. The scatterplot (B) shows the correspondence between modal ratings of expert listeners with the first-rank predictions from the Krumhansl-Schmuckler key-finding algorithm. Points are jittered to avoid overlap. Note that pitch classes are circular (i.e., C is one semitone away from C# and from B) but the plot is not; distances on the axes of (B) should be interpreted accordingly. Fig. 7. Dimensions of musical variation in the NHS Discography. A Bayesian principal components analysis reduction of expert annotations and transcription features (the representations least contaminated by contextual features) shows that these measurements fall along two dimensions (A) that may be interpreted as rhythmic complexity and melodic complexity. Histograms for each dimension (B, C) show he differences — or lack thereof — between behavioral contexts. In (D-G) we highlight excerpts of ranscriptions from songs at extremes from each of the four quadrants, to validate the dimension reduction visually. The two songs at the high-rhythmic-complexity quadrants are dance songs (in blue), while the wo songs at the low-rhythmic-complexity quadrants are lullabies (in green). Healing songs are depicted in red and love songs in yellow. Readers may listen to excerpts from all songs in the corpus at http://osf.io/jmv3q; an interactive version of this plot is available at http://themusiclab.org/nhsplots. moods or themes among the singers and listeners themselves. Fig. 8. The distributions of melodic and rhythmic patterns in the NHS Discography follow power laws. We computed relative melodic (A) and rhythmic (B) bigrams and examined their distributions in the corpus. Both distributions followed a power law; the parameter estimates in the inset correspond to those from the generalized Zipf-Mandelbrot law, where s refers to the exponent of the power law and 6 refers to the Mandelbrot offset. Note that in both plots, the axes are on logarithmic scales. The full lists of bigrams are in Tables S28-S29. cumulative frequencies, are in Tables S28-S29. Fig. S1. Society-wise variation in musical behavior from untrimmed Bayesian principal components analysis. Density estimations of distributions for the principal components of formality, arousal, and narrative dimensions, plotted by society. Distributions are based on posterior samples as aggregated from corresponding ethnographic observations, societies are ordered by the number of available documents in NHS Ethnography from each society (the number of documents per society is displayed in parentheses next to each society name), and distributions are color-coded based on their distance from the global mean (in z-scores; redder distributions are farther from 0, on average). While some societies' means differ significantly from the global mean, each society's distribution nevertheless includes at least one observation at the global mean of 0 on each dimension (dotted lines). Fig. S2. Comparison of within-society variability to across-society differences in musical behavior from untrimmed Bayesian principal components analysis. Each scatterplot includes 60 points, with 95% confidence intervals for both the x- and y-axes. Each point corresponds to the estimated society mean on the principal components (A) formality, (B) arousal, or (C) narrative, presented in units of within-society standard deviations. The dotted lines and shaded region between them represents the conventional significance threshold of +/— 1.96 standard deviations: points appearing outside the shaded region would be interpreted as having larger across-society deviation than within-society variation. The color-coding of the plot by number of available documents describing each society (with red indicating only 1 document) demonstrates that those societies closest to the significance threshold, i.e., those with confidence intervals overlapping with the threshold, should be interpreted with caution. Fig. S3. Comparison of within-society variability to across-society differences in musical behavior. Each scatterplot includes 60 points, with 95% confidence intervals for both the x- and y-axes. Each point corresponds to the estimated society mean on the principal components (A) formality, (B) arousal, or (C) religiosity, presented in units of within-society standard deviations. The dotted lines and shaded region between them represents the conventional significance threshold of +/— 1.96 standard deviations: points appearing outside the shaded region would be interpreted as having larger across-society deviation than within-society variation. However, no societies' means appear outside the shaded region. The color- coding of the plot by number of available documents describing each society (with red indicating only 1 document) demonstrates that those societies closest to the significance threshold, i.e., those with confidence intervals overlapping with the threshold, should be interpreted with caution. In summary: across all NHS Ethnography societies, within-society variability exceeds across-society variability. Fig. S7. Country-wise variation in climate patterns, for comparison to society-wise variation in musical behavior (in Fig. 3). Density estimations of distributions for the Bayesian principal component analysis of climate data, plotted by country. Countries are ordered by the number of available weather stations reporting yearly data (the number of stations per countries is displayed in parentheses next to each country name), and distributions are color-coded based on their distance from the global mean (in z- scores; redder distributions are farther from 0, on average). In contrast to the NHS Ethnography results (Fig. 3), many country-level distributions do not include the global mean of 0, and many distributions differ significantly from 0. Asterisks denote country-level mean differences from the global mean. *p < 05; **p < 01; ***p <001 Fig. S8. Comparison of within-country variation to across-country differences in climate patterns. Each scatterplot includes 60 points, with 95% confidence intervals for both the x- and y-axes. Each point corresponds to the estimated country mean on (A) PC1, (B) PC2, or (C) PC3, presented in units of within- country standard deviations. The dotted lines and shaded region between them represents the conventional significance threshold of +/— 1.96 standard deviations: points appearing outside the shaded region would be interpreted as having larger across-country deviation than within-country variation. Compare to Fig. S3: there is far more across-country variability than within-country variability in the climate dataset, in contrast to NHS Ethnography results. Fig. S9. Associations between song and other behaviors, corrected for bias, and disambiguated by world region. The figure repeats the analyses in the Main Text section "Associations between song and behavior, corrected for bias", within each world region that we studied in the NHS Ethnography. Each plot tests a single hypothesis (e.g., that music is associated with "children"), using the OCM identifier method. The dots indicate the observed frequency of the OCM identifier(s) in the NHS Ethnography, while the vertical lines indicate the confidence interval for the simulated null distribution for the frequency of that OCM identifier(s) from the Probability Sample File. The comparisons are ordered by the number of documents available from each region; the eight pairs of lines and points that appear in each panel correspond to the eight eHRAF world regions (in order from fewest to most documents: Middle East, Middle America and the Caribbean, Europe, South America, Oceania, North America, Asia, Africa). Comparisons in blue show a significant association between vocal music and the hypothesis, afte correcting for multiple comparisons (p < .05). While the results largely replicate within each world region, there is a clear relation between whether or not the region-wise analysis replicates and the number of documents available about the hypothesized association. For example, the behavioral context "infant care" has a significant association with music over all regions, but only replicates in half the region-wise analyses; the replication is successful in the two regions with the most documents available, however. Note that this analysis poses serious issues of statistical power: in many cases, the hypothesis tests are based on fewer than 10 reports from a single region. It should thus be interpreted with caution. Fig. S11. Bayesian principal components analysis posterior diagnostics (posterior means). Each panel corresponds to posterior samples for the latent mean of an ethnographic annotation a from the Gibbs sampler described in SI Text 2.1.4. Each color corresponds to one of three chains (red, green, and blue). In Markov-chain Monte Carlo methods, successive iterations of a chain are autocorrelated; the diagnostic plot shows that the chain has sufficiently converged to the target distribution (i.e., the true posterior) within the number of iterations used. The plot shows that the chains are well-mixed and fully explore the posterior of each parameter, meaning that posterior means and credible intervals can be interpreted with confidence. Fig. $12. Bayesian principal components analysis posterior diagnostics (posterior means). Posterior samples for the latent residual variance o”, shared across all ethnographic annotations, from the Gibbs sampler described in SI Text 2.1.4. Each color corresponds to one of three chains (red, green, and blue). In Markov-chain Monte Carlo methods, successive iterations of a chain are autocorrelated; the diagnostic plot shows that the chain has sufficiently converged to the target distribution (i.e., the true posterior) within the number of iterations used. The plot shows that the chains are well-mixed and fully explore the posterior of each parameter, meaning that posterior means and credible intervals can be interpreted with confidence. Fig. $13. Bayesian principal components analysis posterior diagnostics (posterior means). Each panel corresponds to posterior samples for the loading of an ethnographic annotation onto latent dimension 1, W «aq from the Gibbs sampler described in SI Text 2.1.4. Each color corresponds to one of three chains (red, green, and blue). In Markov-chain Monte Carlo methods, successive iterations of a chain are autocorrelated; the diagnostic plot shows that the chain has sufficiently converged to the target distribution (i.e., the true posterior) within the number of iterations used. The plot shows that the chains are well-mixed and fully explore the posterior of each parameter, meaning that posterior means and credible intervals can be interpreted with confidence. Fig. S14. Bayesian principal components analysis posterior diagnostics (posterior means). Each panel corresponds to posterior samples for the loading of an ethnographic annotation onto latent dimension 2, W «q from the Gibbs sampler described in SI Text 2.1.4. Each color corresponds to one of three chains (red, green, and blue). In Markov-chain Monte Carlo methods, successive iterations of a chain are autocorrelated; the diagnostic plot shows that the chain has sufficiently converged to the target distribution (i.e., the true posterior) within the number of iterations used. The plot shows that the chains are well-mixed and fully explore the posterior of each parameter, meaning that posterior means and credible intervals can be interpreted with confidence. Fig. S15. Bayesian principal components analysis posterior diagnostics (posterior means). Each panel corresponds to posterior samples for the loading of an ethnographic annotation onto latent dimension 3, W «a from the Gibbs sampler described in SI Text 2.1.4. Each color corresponds to one of three chains (red, green, and blue). In Markov-chain Monte Carlo methods, successive iterations of a chain are autocorrelated; the diagnostic plot shows that the chain has sufficiently converged to the target distribution (i.e., the true posterior) within the number of iterations used. The plot shows that the chains are well-mixed and fully explore the posterior of each parameter, meaning that posterior means and credible intervals can be interpreted with confidence. Table S1. Codebook for society identifiers. Table S2. Codebook for NHS Ethnography metadata. Table S3. Codebook for NHS Ethnography free text. Table S4. Codebook for NHS Ethnography primary annotations. Table S5. Codebook for NHS Ethnography secondary annotations. Table S6. Codebook for NHS Ethnography scraping. lable S8. Codebook for NHS Discography music information retrieval features. Music information etrieval data are computed for both the full audio (denoted by the prefix "f_") and the 14-sec excerpt ised in previous research (54) (denoted by the prefix "ex_"). For computational details, please see (132) ind (133). Table S9. Codebook for NHS Discography naive listener annotations. Table S11. Codebook for NHS Discography transcription features. Table S13. Variable loadings for NHS Ethnography PC1 (Formality). All variables from the trimmed model are shown. Missingness refers to the proportion of observations with missing values for the corresponding variable. Uniformity refers to the proportion of observations with the value "1" (for binary variables only). Readers may use the NHS Ethnography Explorer interactive plot at http://themusiclab.org/nhsplots to validate the interpretation of this and other dimensions. Table S14. Variable loadings for NHS Ethnography PC2 (Arousal). All variables from the trimmed model are shown. Missingness refers to the proportion of observations with missing values for the corresponding variable. Uniformity refers to the proportion of observations with the value "1" (for binary variables only). Readers may use the NHS Ethnography Explorer interactive plot at http://themusiclab.org/nhsplots to validate the interpretation of this and other dimensions. Table S19. Word lists for bias-corrected association tests. Table S20. Cross-cultural associations between song and other behaviors, with control analysis of frequency-matched OCM identifiers. We tested 20 hypothesized associations between song and other behaviors, using two methods that both compare the frequency of a behavior in song-related passages to comparably-sized samples of other ethnography from the same sources, but that are not about song (see Table 2). This table du plicates the OCM identifier findings (columns 2-4) and compares them to 20 "control" tests of OCM identifiers that appear in the Probability Sample File (see SI Text 2.2.2) that are not expected to be associated with song. The control OCM identifiers are listed, along with tests of their association with song t hat take the same format as the main hypothesis tests. Frequencies listed are counts from an automated search for song-related keywords in the full Probability Sample File or from a simulated null distribu ion based on sampling an equal number of passages in the same document proportions as song-re ated passages. ***p < 001, **p < .01, *p < .05, using adjusted p-values; 95% confidence intervals are in brackets. Table S22. Summary information for NHS Discography societies and recordings. This table is reprinted from (54). Table S30. List of Outline of Cultural Materials identifiers used by secondary annotators in NHS Ethnography. To facilitate manual annotations using these topics, we combined and/or summarized several identifiers, which showed evident overlap between annotators in pilot work.